上交大等探索键值压缩的边界:MILLION开源框架定义模型量化推理新范式,入选顶会DAC 2025
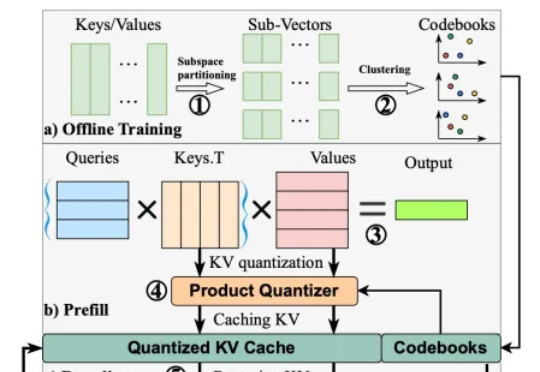
上交大等探索键值压缩的边界:MILLION开源框架定义模型量化推理新范式,入选顶会DAC 2025在以 transformer 模型为基础的大模型中,键值缓存虽然用以存代算的思想显著加速了推理速度,但在长上下文场景中成为了存储瓶颈。为此,本文的研究者提出了 MILLION,一种基于乘积量化的键值缓存压缩和推理加速设计。
来自主题: AI技术研报
9805 点击 2025-04-30 08:32